Reinforcement Learning in Python
Implementing Reinforcement Learning (RL) Algorithms for global path planning in tasks of mobile robot navigation. Comparison analysis of Q-learning and Sarsa algorithms fo the environment with cliff, mouse and cheese.
![]()
Reference to:
Valentyn N Sichkar. Reinforcement Learning Algorithms for global path planning // GitHub platform. DOI: 10.5281/zenodo.1317898
Related works:
-
Sichkar V.N. Comparison analysis of knowledge based systems for navigation of mobile robot and collision avoidance with obstacles in unknown environment. St. Petersburg State Polytechnical University Journal. Computer Science. Telecommunications and Control Systems, 2018, Vol. 11, No. 2, Pp. 64–73. DOI: 10.18721/JCSTCS.11206 (Full-text available also here ResearchGate.net/profile/Valentyn_Sichkar)
-
The research results for Neural Network Knowledge Based system for the tasks of collision avoidance is put in separate repository and is available here: Matlab implementation of Neural Networks
-
The study of Semantic Web languages OWL and RDF for Knowledge representation of Alarm-Warning System is put in separate repository and is available here: Knowledge Base Represented by Semantic Web Language
-
The study of Neural Networks for Computer Vision in autonomous vehicles and robotics is put in separate repository and is available here: Neural Networks for Computer Vision
Description
RL Algorithms implemented in Python for the task of global path planning for mobile robot. Such system is said to have feedback. The agent acts on the environment, and the environment acts on the agent. At each step the agent:
- Executes action.
- Receives observation (new state).
- Receives reward.
The environment:
- Receives action.
- Emits observation (new state).
- Emits reward.
Goal is to learn how to take actions in order to maximize the reward. The objective function is as following:
Q_[s_, a_] = Q[s, a] + λ * (r + γ * max(Q_[s_, a_]) – Q[s, a]),
where,
Q_[s_, a_] - value of the objective function on the next step,
Q[s, a] - value of the objective function on the current position,
max(Q_[s_, a_]) – Q[s, a]) - choosing maximum value from the possible next steps,
s – current position of the agent,
a – current action,
λ – learning rate,
r – reward that is got in the current position,
γ – gamma (reward decay, discount factor),
s_ - next chosen position according to the next chosen action,
a_ - next chosen action.
The major component of the RL method is the table of weights - Q-table of the system state. Matrix Q is a set of all possible states of the system and the system response weights to different actions. During trying to go through the given environment, mobile robot learns how to avoid obstacles and find the path to the destination point. As a result, the Q-table is built. Looking at the values of the table it is possible to see the decision for the next action made by agent (mobile robot).
Experimental results with different Environments sre shown and described below.
Code is supported with a lot of comments. It will guide you step by step through entire idea of implementation.
Each example consists of three files:
- env.py - building an environment with obstacles.
- agent_brain.py - implementation of algorithm itself.
- run_agent.py - running the experiments.
Content
Codes (it’ll send you to appropriate folder on GitHub):
Experimental results (figures and tables on this page):
- RL Q-Learning Environment-1. Experimental results
- Q-learning algorithm resulted chart for the environment-1
- Final Q-table with values from the final shortest route for environment-1
- RL Q-Learning Environment-2. Experimental results
- Q-learning algorithm resulted chart for the environment-2
- Final Q-table with values from the final shortest route for environment-1
- RL Q-Learning Environment-3. Experimental results
- Comparison analysis of Q-Learning and Sarsa algorithms
RL Q-Learning Environment-1. Experimental results
Environment-1 with mobile robot, goal and obstacles


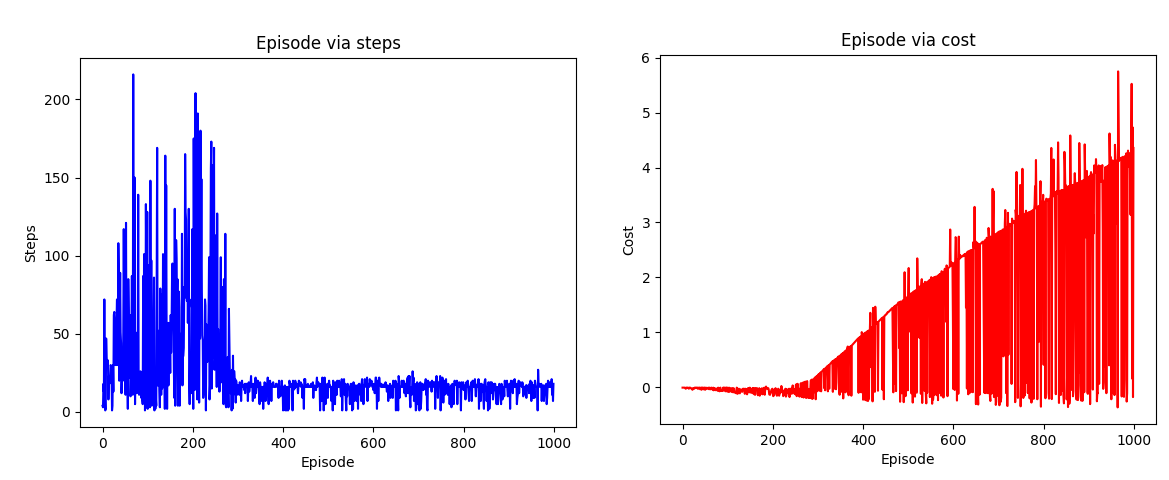
Q-learning algorithm resulted chart for the environment-1
Represents number of episodes via number of steps and number of episodes via cost for each episode
Q-table with values from the final shortest route for environment-1
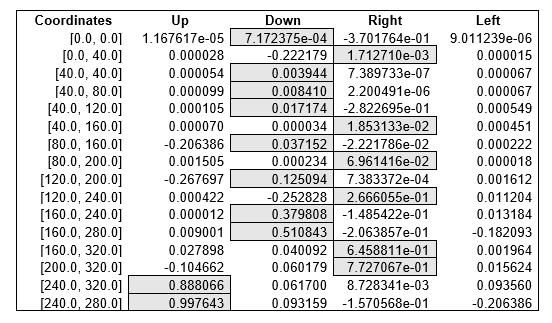
Looking at the values of the table we can see the decision for the next action made by agent (mobile robot). The sequence of final actions to reach the goal after the Q-table is filled with knowledge is the following: down-right-down-down-down-right-down-right-down-right-down-down-right-right-up-up.
During the experiment with Q-learning algorithm the found shortest route to reach the goal for the environment-1 consist of 16 steps and the found longest rout to reach the goal consists of 185 steps.
RL Q-Learning Environment-2. Experimental results
Bigger environment-2 with more obstacles

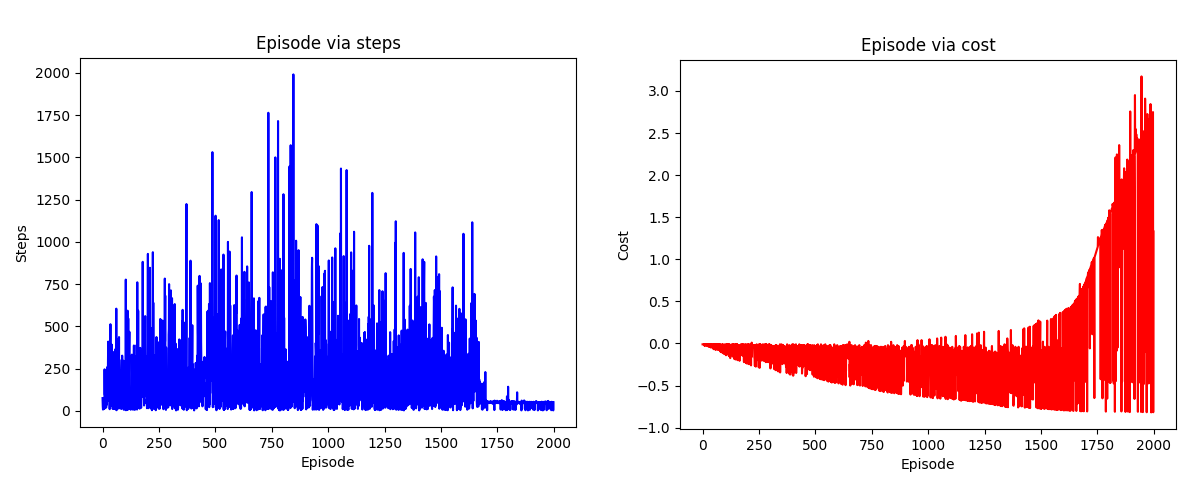
Q-learning algorithm resulted chart for the environment-2
Represents number of episodes via number of steps and number of episodes via cost for each episode
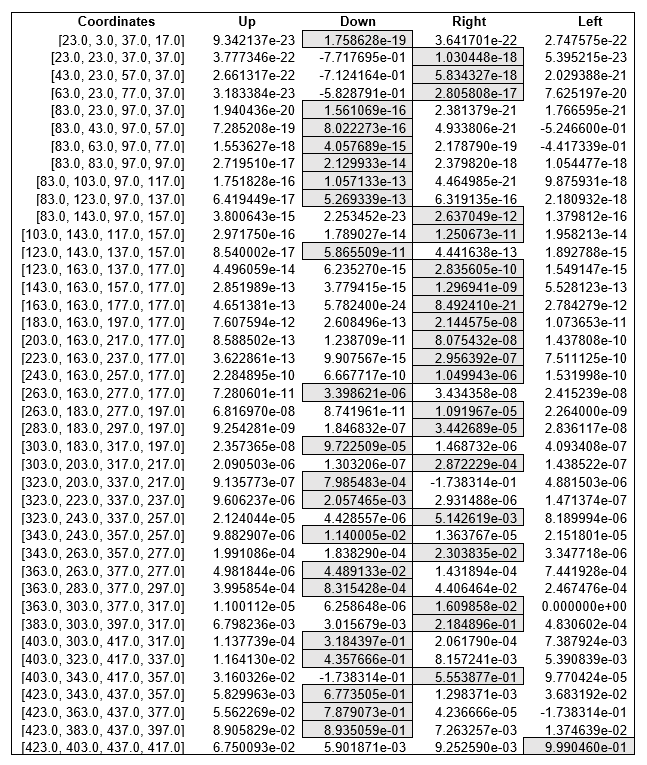
Q-table with values from the final shortest route for environment-1
RL Q-Learning Environment-3. Experimental results
Super complex environment-3 with a lot of obstacles

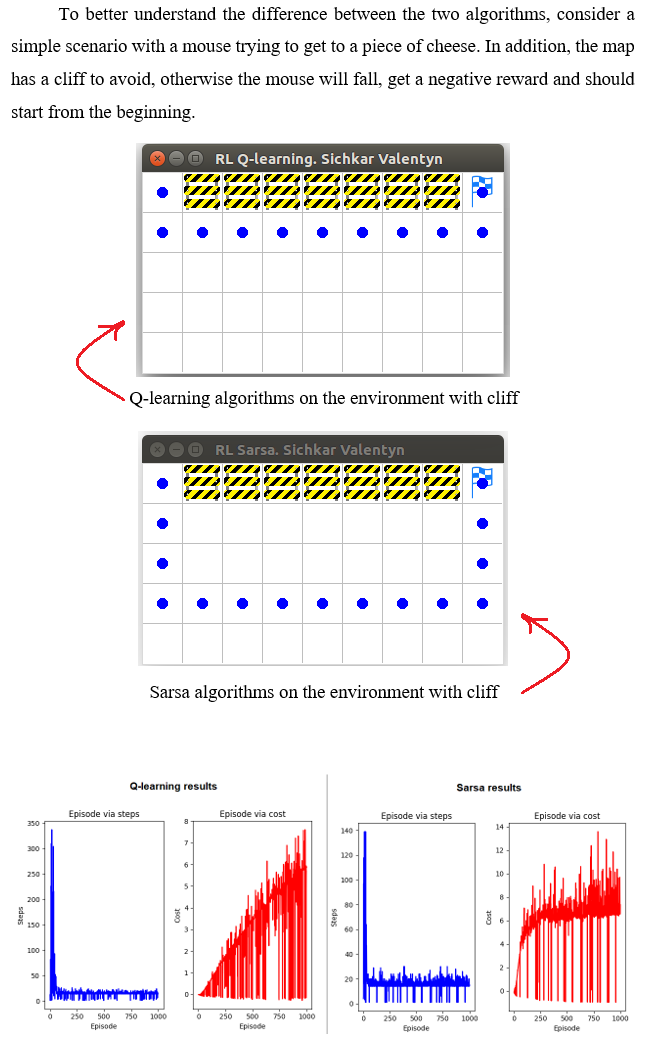
Comparison analysis of Q-Learning and Sarsa algorithms
MIT License
Copyright (c) 2018 Valentyn N Sichkar
github.com/sichkar-valentyn
Reference to:
Valentyn N Sichkar. Reinforcement Learning Algorithms for global path planning // GitHub platform. DOI: 10.5281/zenodo.1317898